
Every lender in 2026 wants the same outcome: Shorter cycle times. But reality plays out differently with the operations team at work.
The files show up as mixed PDFs. A few pages are upside down. The borrower uploaded two pay stubs, one bank statement, and a “mystery” document that is really a retirement distribution statement. The LOS has one address. The docs have three. Someone starts ‘stare-and-compare’ and the clock starts leaking.
If lenders want real speed, they would have to treat automated document classification as a manufacturing control point, not a small intake task. It is the step that decides whether the rest of the process runs smoothly, or bounces back and forth across teams and systems.
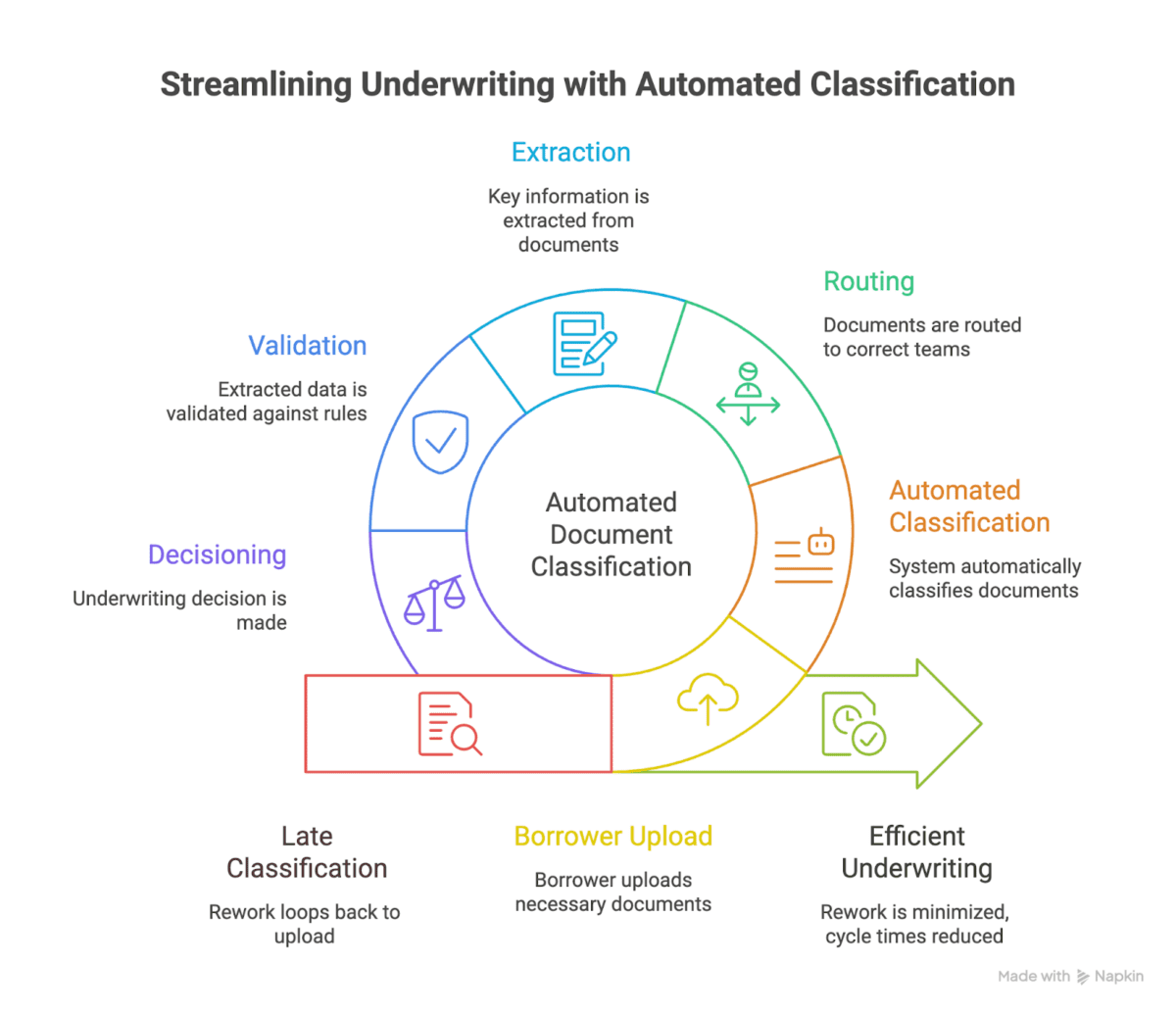
Why automated document classification can cause a bottleneck for cycle time
Mortgage manufacturing is full of decisions that depend on ‘what is this document’
- Is this a pay stub, a W-2, a VOE, or a payroll summary?
- Is this a bank statement, a transaction history, or a screenshot?
- Is this the most recent version, or an older copy?
- Is this a borrower doc, a third-party doc, or a lender-generated doc?
- Does it map to an eFolder container and naming convention your downstream systems accept?
When classification is late or messy, the cost shows up in three places:
- Rework loops: Mortgage teams spend time routing, renaming, re-stacking, and asking borrowers for ‘the right doc’ when the doc was already there.
- Bad data early, bad decisions later: If a doc is misclassified, extracted data can still look ‘reasonable’ but it belongs to the wrong bucket. That is how small errors turn into big clears-to-close delays.
- QC drag: Manual QC becomes a permanent tax because nobody trusts the file.
Steve calls out the core failure mode: ‘If you’re going to require a human to sort of deal with the output in mortgage, then are you really getting a lift?’
Automated document classification is really a data quality decision
Most teams talk about automated document classification like it is ‘tagging’.
In practice, it is a data quality decision. Because the moment you classify, you are also deciding what must be true next:
- Which checklist rules apply
- Which calculations can start
- Which exceptions matter
- Which investor or GSE delivery constraints you have to satisfy
Automated document classification is the earliest place you can enforce that consistency at scale.
The business case: production costs are still too high to tolerate manual intake
Freddie Mac’s 2025 update to its cost-to-originate analysis says:
‘The cost to originate loans continues to rise, but lenders using LPA digital capabilities save $1,700 per loan.’
Lenders are being pushed to find repeatable savings per loan, and ‘digital capabilities’ that cut cycle time are one of the few levers that scale. Connecting that back to automated document classification makes it the front door to:
- document indexing and routing
- extraction and validation
- condition identification and clearing
- continuous QC

What ‘good’ automated document classification looks like in mortgage operations
If you want automated document classification that matters in production, define the output in business terms, not model terms.
At minimum, a “good” classification output includes:
1) Document type, with a mortgage-native taxonomy
Mortgage-native matters because you are not classifying “a PDF.” You are classifying it into the same document vocabulary your investors, MI partners, and QC processes already use. MISMO’s work is a reminder that the industry has spent years building shared definitions so systems can exchange mortgage data with less friction.
2) Document purpose and workflow role
A paystub can be used for qualifying income, employment confirmation, or conditions support. A bank statement can be for assets, reserves, or large deposit sourcing. Classification that builds intent into the purpose of automation encourages better clarity in the downstream process.
3) Version and time relevance
Mortgage is version-driven. The ‘right’ doc is often ‘the most recent doc’. Classification should support versioning along with ‘latest’ logic, not leave it as tribal knowledge. At TRUE, document indexing AND versioning are considered important as part of the core MOS platform.
4) Routing-ready packaging for your systems of record
This is where projects either scale or stall. You can have a great classifier and still fail if you cannot map output to your LOS, eFolder, and naming rules. Fannie Mae’s Loan Quality Connect job aid is blunt about how strict this can be. It says loan file names “must start with the Fannie Mae Loan Number” and follow a defined pattern for documents to process correctly.
That is a simple example of a bigger truth: classification has to land in the real constraints of mortgage tech stacks.
Automated document classification and ‘lights-out’ processing
There is a difference between ‘less manual’ and ‘machine-only’. MISMO’s document work makes the goal clear by describing SMART Doc capabilities as follows:
‘The SMART document provides data formatting and transformation for true lights-out processing.’ You may not be moving every doc format to a MISMO v3 envelope tomorrow, but that definition is the endgame to make downstream logic safe to run without human triage.
A C-suite checklist for evaluating automated document classification
If you are a COO, CIO, Head of Ops, or Head of Underwriting, you can qualify your document classification automation efforts with this simple set of questions.
1) Can it handle messy borrower uploads in production?
Ask for evidence on:
- mixed PDFs
- mobile photos
- duplicates and partial docs
- missing pages
- rotated pages
2) What is the exception path, and who owns it?
Every classifier has exceptions. The question is whether exceptions create:
- a new queue
- a new role
- a new tool specialist
Or whether exceptions are handled inside a workflow your teams already run.
3) Does it map to your real doc naming and eFolder constraints?
If your investor delivery or QC tooling has naming rules like Fannie Mae’s, can the output comply by default?
4) Can it prove consistency across systems early?
This is the ‘clean data’ test. If the LOS says one thing and the docs say another, does the system surface it early enough to matter?
5) Can it support a downhill manufacturing model?
This is the end state that True’s CEO Steve points to, using manufacturing as the mental model. Automated document classification is one of the first steps that must behave ‘downhill’ for the rest to follow.
Where automated document classification should go next
Most lenders are still measuring classification as ‘doc-type accuracy’. That is a narrow definition which can improve rework loops, but does not extend itself to catching issues early. The next phase in measuring classification is to tangibly measure the following set of metrics:
- time to routing-ready file
- time to trusted data
- conditions cleared without human triage
- defect reduction
- cycle time compression without adding staff
Eventually, the automated document classification efforts should lead to improve the primary objective: reduce the cost per loan manufactured without sacrificing loan data quality.


